Implementing Usage-Based Billing with Hightouch and the Cloud Data Warehouse
This playbook will show you how to build usage-based billing process for SaaS products.
Made by: Hightouch



DISCLAIMER: OpenAI's ChatGPT does NOT use Hightouch to power its usage-based-billing. Hightouch is not a complete solution for usage-based-billing. This is just a hypothetical example to inspire data & operations teams that are tasked with similar challenges using billing data in their warehouse.
Implementing a usage-based billing system has considerable benefits for companies and customers alike as it aligns price with the value users believe they get as they pay only for what they need. Companies like Slack and Datadog have helped usher in the popularity of a usage-based pricing model.
However, setting up usage-based billing historically meant investing in significant engineering resources to build complex and scalable data pipelines from the ground up.
With Hightouch, you can roll your own usage-based-billing using th cloud data warehouse to sync product usage data directly into billing applications like NetSuite and Stripe to generate invoices.
The example in this playbook revolves around an imaginary service called ChatAI, modeled after OpenAI's ChatGPT, a service that's been exploding in popularity in the last few months (as of January 2023). If you haven't heard of ChatGPT yet, learn more here— it's quite fascinating. As a disclaimer, ChatGPT is not a customer of Hightouch, and this is just a simplified example.
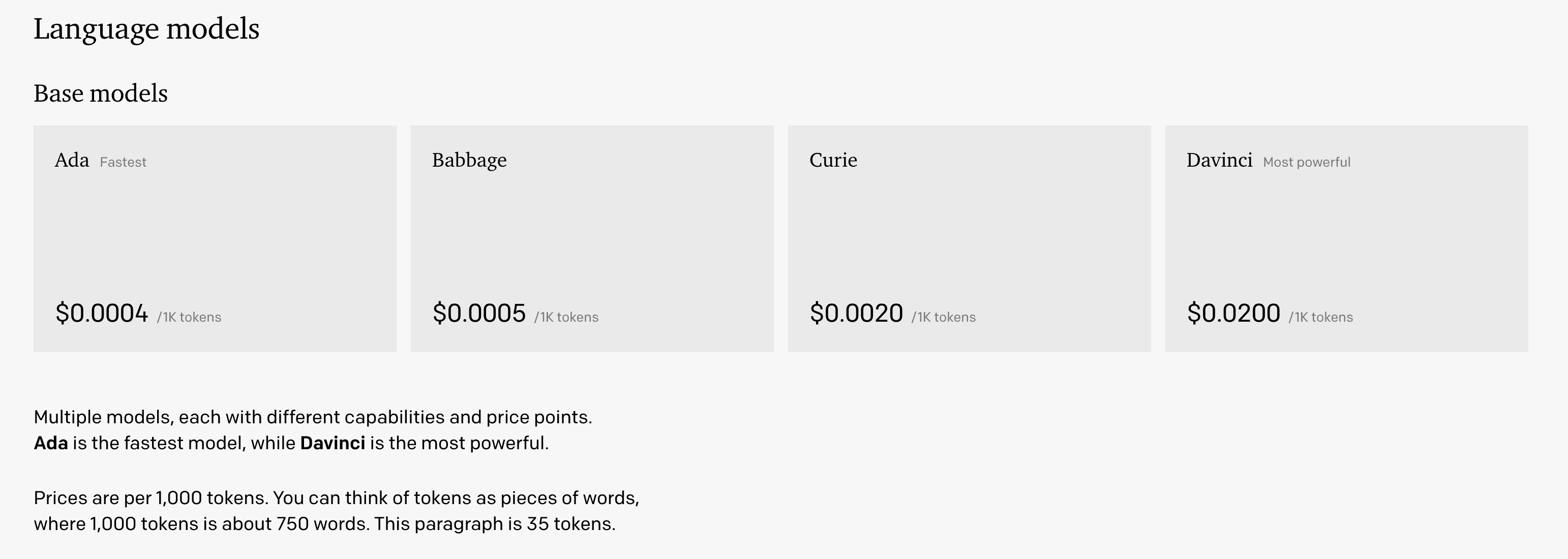
Similar to ChatGPT, our imaginary service called ChatAI has to run an expensive language model behind-the-scenes. To cover expenses, ChatAI utilizes usage-based pricing, charging users a fixed amount per model dependent on the number of tokens.
In this guide, you’ll learn how to create fast and scalable usage-based pricing for companies. This guide will show how you can collect the needed event data, how you can aggregate event data into billable metrics, and how you can integrate with various components of your billing stack, from payment collection to invoice creation and alerts.
We recommend taking a modern data stack approach using a cloud data warehouse, such as Snowflake, and an event collection library, such as Snowplow. Without the cloud data warehouse approach, sending events via an API could result in potential network issues or process crashes while using an all-in-one usage-based billing platform could lead to usage events getting lost, directly translating into lost revenue.
While some API-based services have a fixed price per request, the pricing model of many businesses are more complex. For example, our imaginary service called ChatAI has a billing model that is dependent on the language model used and the number of tokens in the request (e.g., the prompt and response.)
Using an event streaming API like Snowplow, you can append a new row to your warehouse for each request and capture the following fields:
- transaction_id (string) - unique identifier for each event
- customer_id (string) - which customer this event applies to (this could be a Stripe ID)
- timestamp (string) - when the event happened
- event_type (string) - the kind of event (e.g., language_model or image_model)
- properties (object) - key/value pairs with details of the event
The first four fields are relatively standard across all events. The properties object may vary depending on the event type. To build out pricing for ChatAI, you will need to know the model type used as well as the number of tokens in the request. If you were building pricing for DALL-E, you could simply record the resolution of the image.
- transaction_id:
1234 - customer_id:
abcd - timestamp:
2022-10-12T07:20:50.52Z - properties:
{token_count: 1200, model_type: “davinci”}
While each event log provides detailed information about every API request, you need to calculate aggregate usage to be useful for billing teams and customers. In a query, you can aggregate events by model type on a daily and monthly level. Snowflake’s documentation highlights how you can aggregate monthly with window functions.
select **customer_id**,
date(**timestamp**) as **timestamp**,
**properties**:model_type,
sum(**properties**:token_count) as daily_records
sum(daily_records) OVER (PARTITION BY **customer_id**, date_trunc('month', **timestamp**) ORDER BY **timestamp**) AS cum_monthly_records
from RAW.AMPLITUDE.EVENT
where event_type = 'language_model'
group by 1,2,3
order by 1,2,3 desc
aggregate_usage
Definitions:
- daily tokens (number): the sum of how many tokens were used on a specific day
- agg_monthly_tokens (number): the sum of all tokens used up to that day of the month (inclusive)
You get the following outcome.
- customer_id:
1234 - date:
Jan 12, 2023 - model_type:
ada - daily_tokens:
100 - agg_monthly_tokens:
1460
It may seem like a lot of computation to recalculate from the raw event log every time, but there are numerous benefits to having stateless calculations. Rather than incrementing or decrementing a counter for every event, you always maintain a single source of truth. This introduces:
- Increased accuracy: Maintaining usage data in two separate systems can often lead to differences requiring reconciliation. Directly updating your billing metrics with the raw event logs helps you ensure your billable metric is accurate.
- Increased auditability: Auditing is critical whenever billing is involved for both customer experience and compliance purposes. You can always analyze your invoices by going back to our event logs.
- Calculation logic at any time: Suppose traffic exceeded what expected on ChatAI's launch causing processing to slow down, and they wanted to exclude all requests that took over 1,200 ms to respond; You can easily filter out those events in one line with an aggregate query.
Going from events to aggregate usage is one step closer to billing your customers, but you’ll need to translate usage to actual dollars. There are two options to do this.
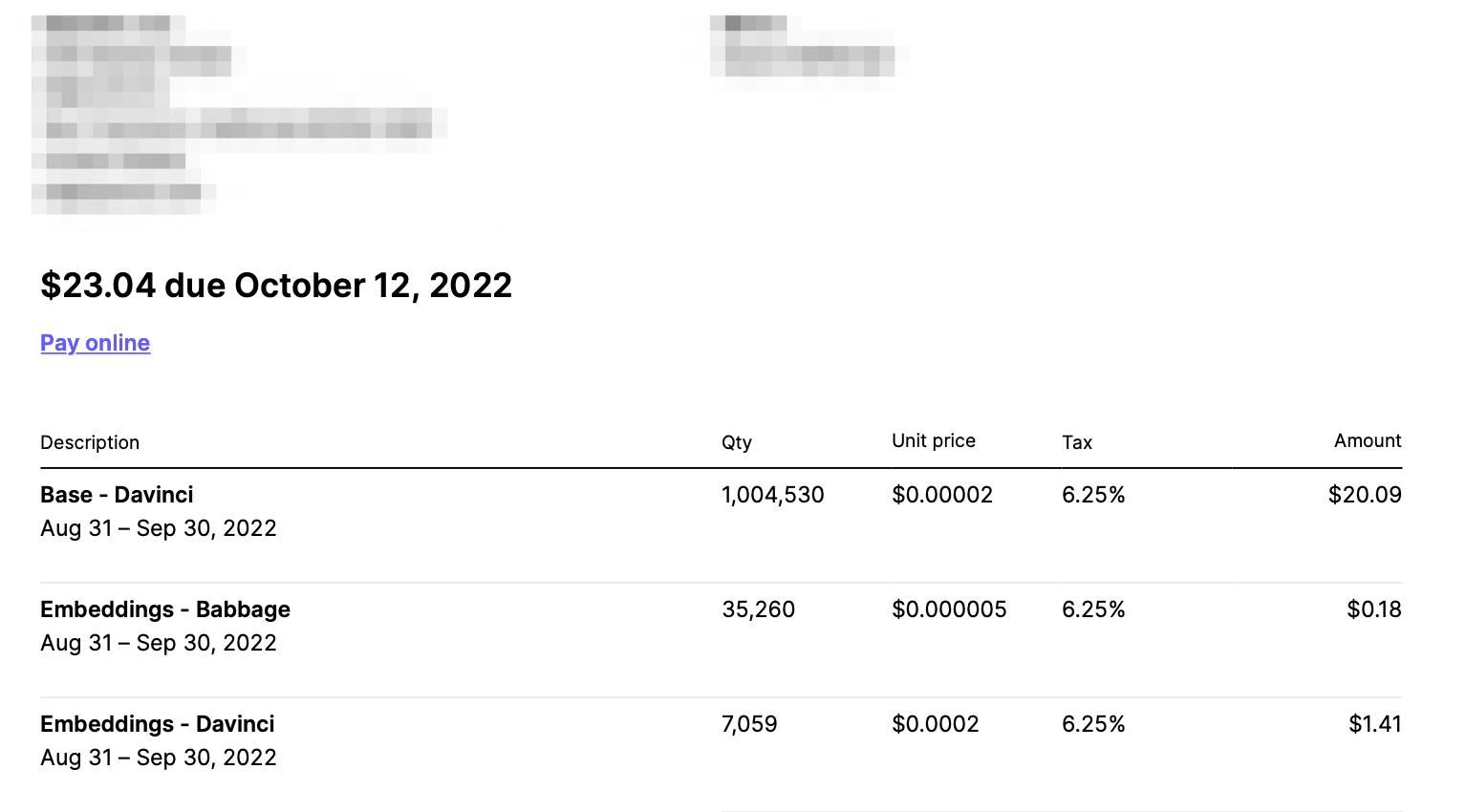
The first option is sending all charges to an invoicing platform. To do this you'll need to create a model.
SELECT
object_construct('internalId', customer_id) AS customer_id,
CURRENT_DATE() AS invoice_date,
'ChatAI Demo Invoice' AS memo,
CONCAT(au.customer_id, invoice_date) AS _id,
object_construct(
'item',
ARRAY_AGG(
object_construct(
'quanity',
monthly_token_count,
'rate',
bi.rate,
'item',
bi.ns_id
)
)
) AS items
FROM
AGGREGATE_USAGE au
JOIN AI_BILLING_INFO bi ON au.model_type = bi.model_type
GROUP BY 1, 2, 3, 4
At the end of every billing cycle, you will create an invoice.
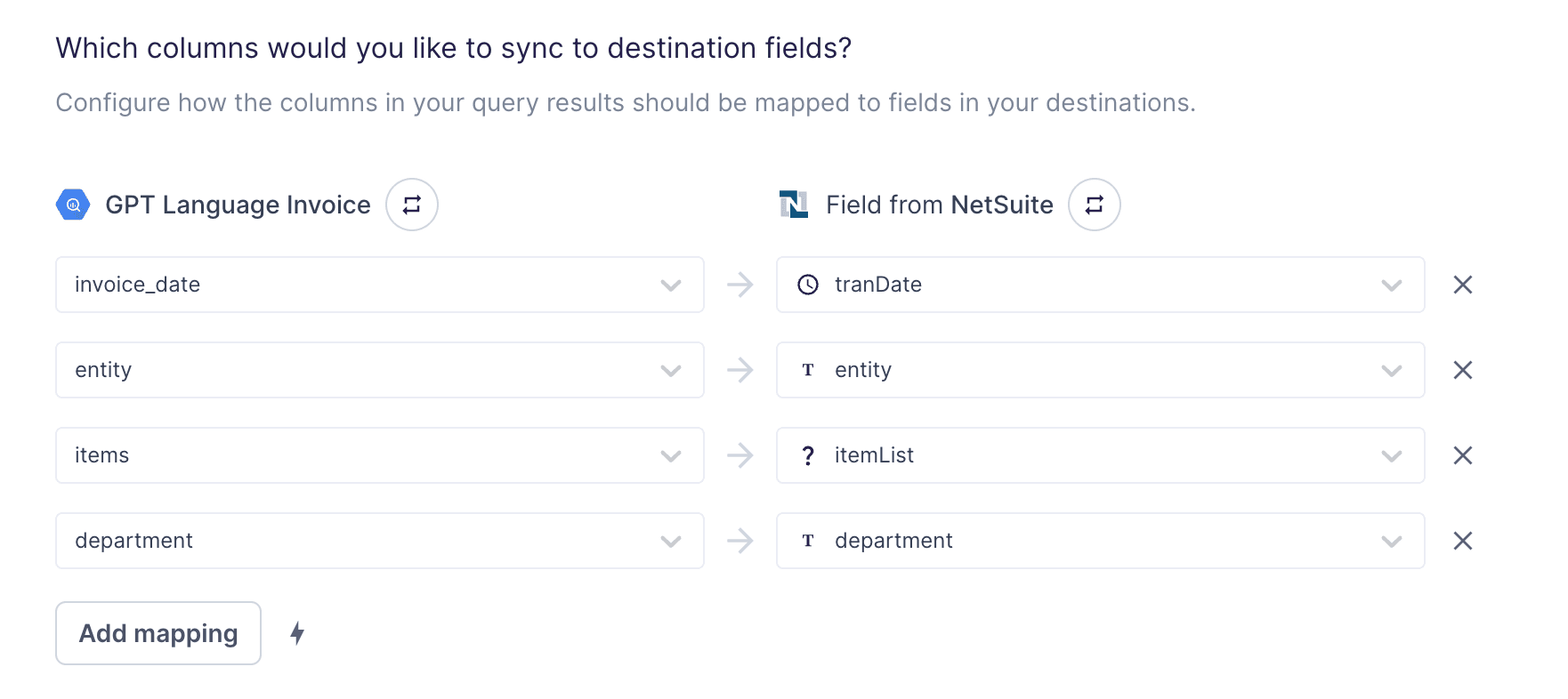
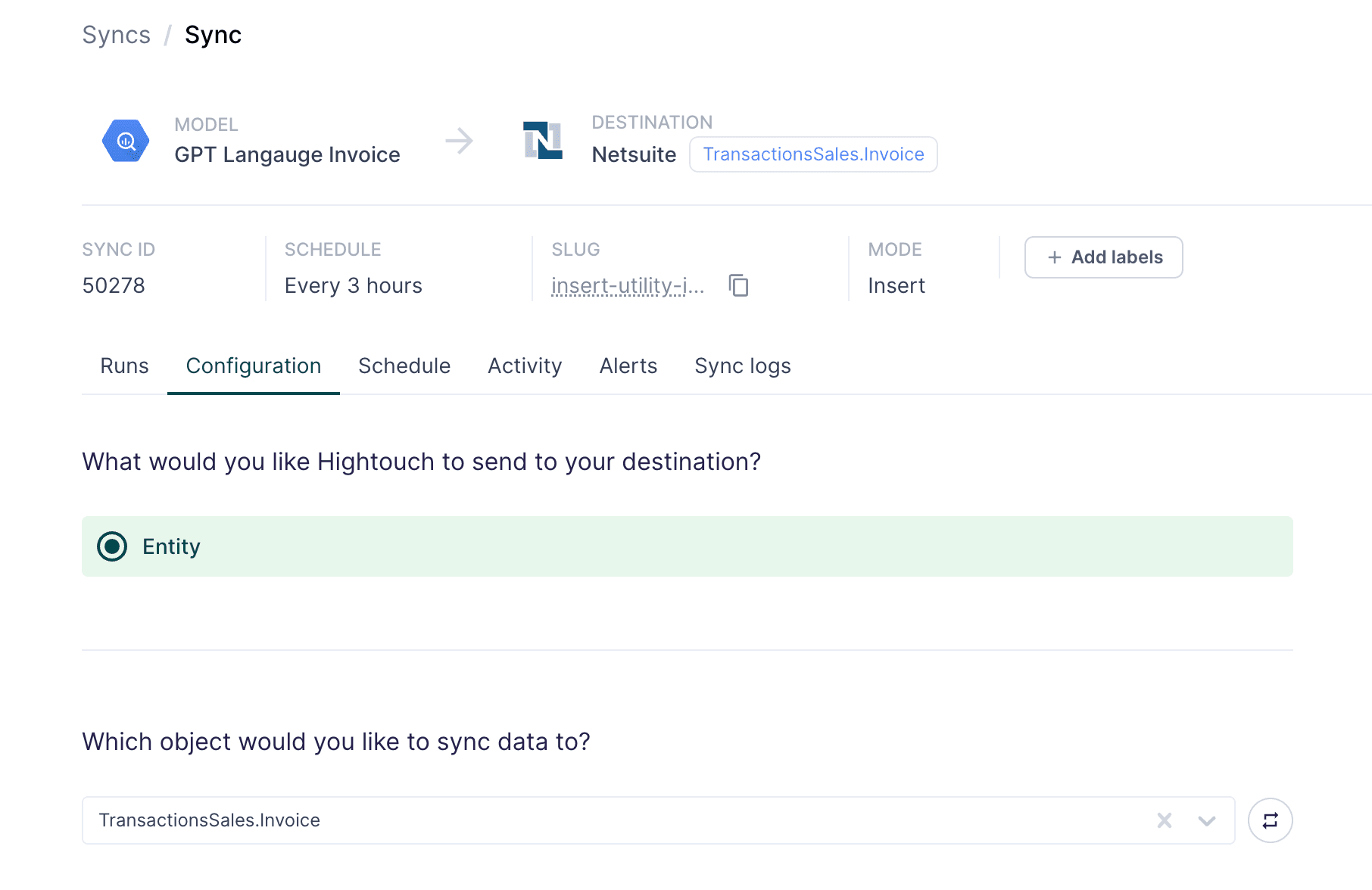
The second option is sending usage data to a subscription management platform.
When companies start to expand their product lines or have specialized pricing for enterprise customers, it makes sense to migrate to a subscription management platform. These platforms enable you to configure custom prices, plans, and products. The most common integrations are with Stripe and NetSuite, but many subscription management platforms like Metronome or Orb exist.
This example is based on Stripe, but most platforms have similar interfaces. Once you’ve configured your customers and subscriptions within Stripe, you can report usage via the Usage Records table within Hightouch.
Starting from your aggregate_usage record table above, you can join the customer_id and model_type to find the associated Stripe subscription_item_id.
From there you you'll need to create a usage record model.
SELECT ss.subscription_item_id, au.daily_tokens, au.date AS timestamp_
FROM aggegrate_usage au
JOIN stripe_subscriptions ss ON ss.customer_id = au.customer_id
AND ss.product = au.model_type
- subscription_item_id:
1234 - daily_tokens:
3682 - timestamp_:
167391672
With a usage record model created, the last step is to map your model to the Stripe usage record table.
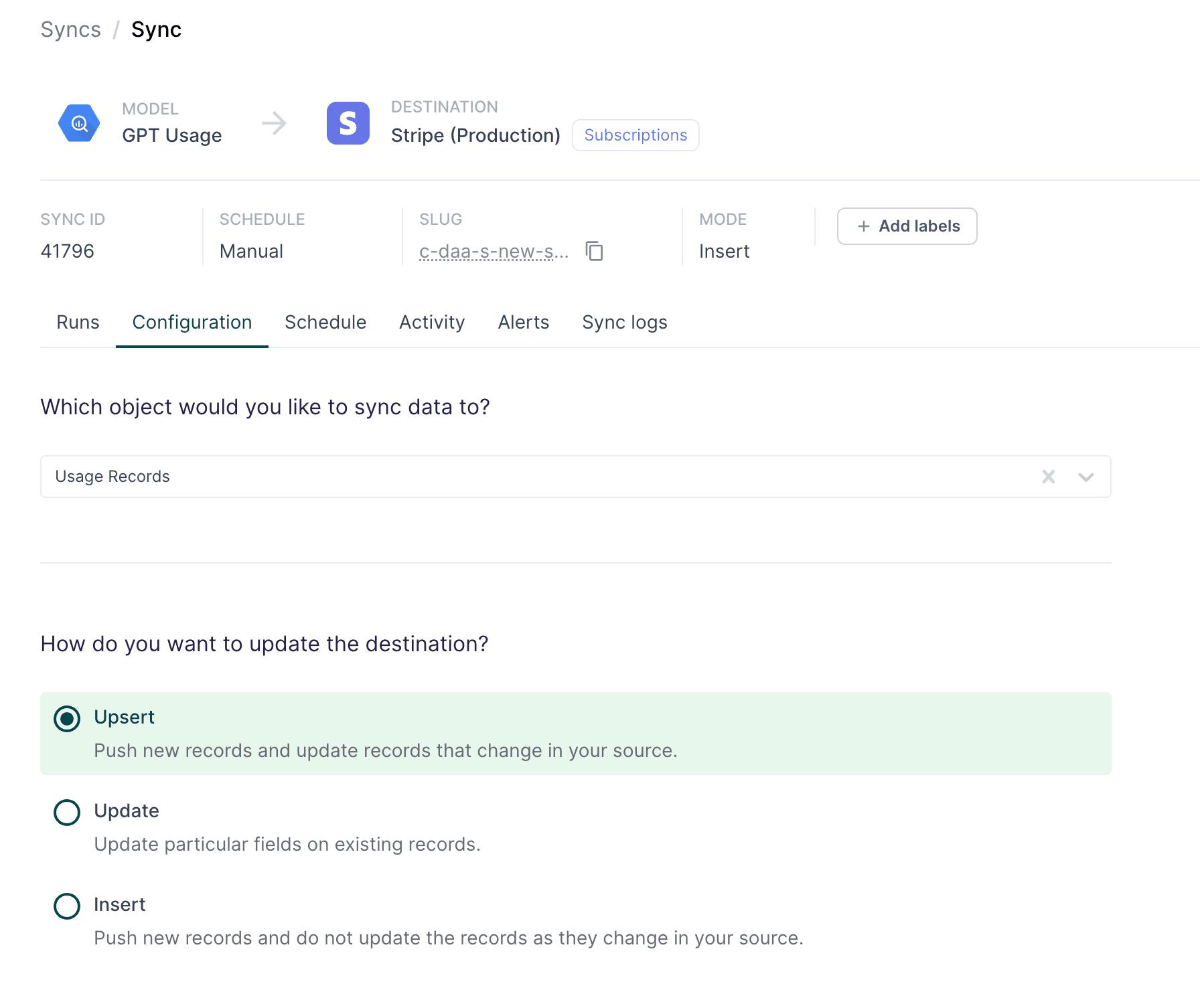
After selecting the Usage Record table, you only need four fields to update the usage record:
- Subscription Item (string): Subscription Items map a customer to pricing plan
- Quantity (integer): The usage quantity for the specified date
- Timestamp (timestamp): The timestamp when this usage occurred
- Action (enum): Increment or Set the usage record for the timestamp
Beyond collecting payments, there are many other ways Hightouch can support usage-based billing. For example, you could display usage to your customers so they know what to expect when their invoices are sent out.
While Snowflake is perfect for calculating aggregate usage, it’s too slow to load from every time a customer visits their billing dashboard. To speed up load times, you can sync your usage table to your production database using Hightouch. This also makes it easy for your engineers since they can use the same database they are currently working in instead of pulling data from an API.
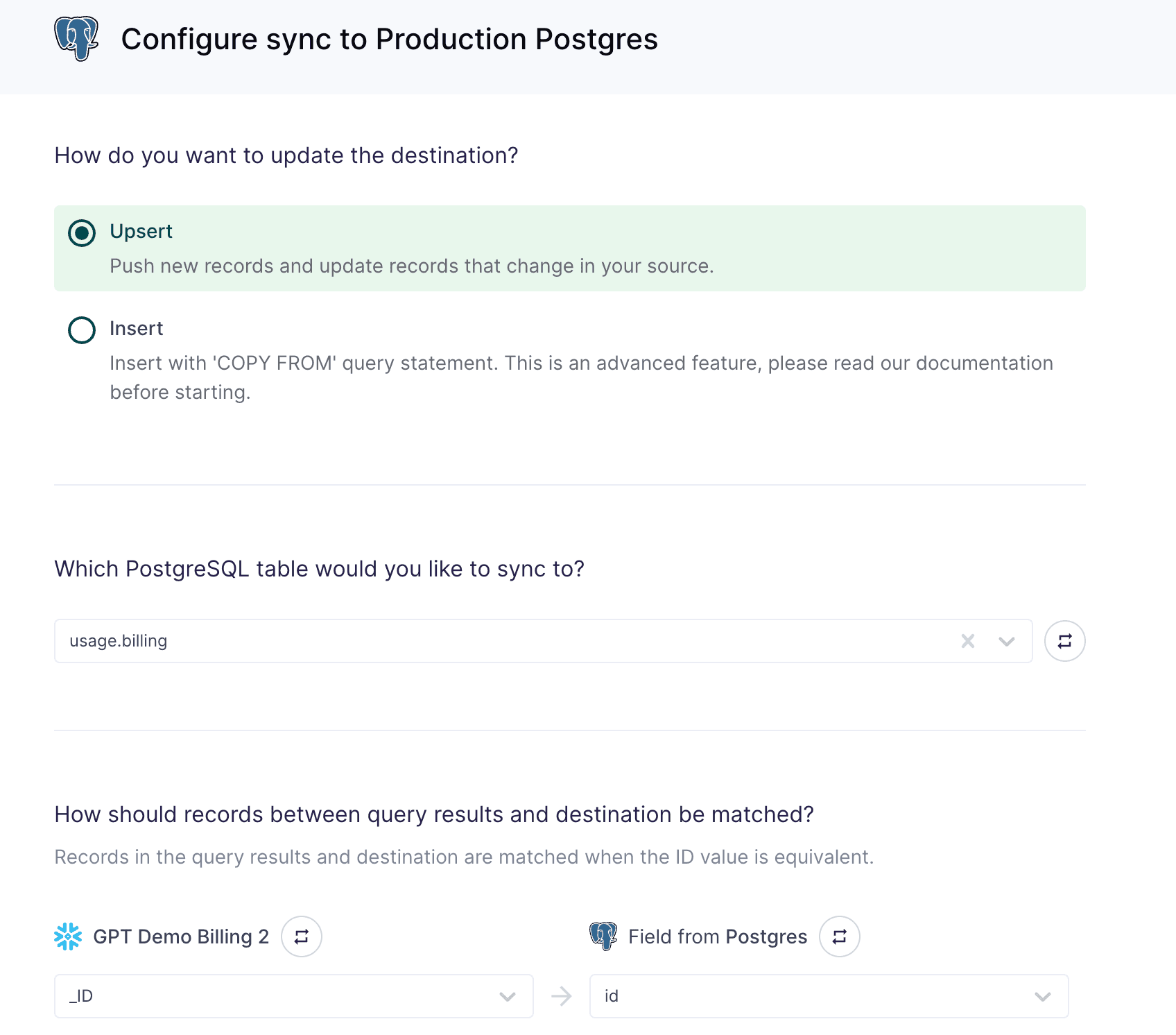
You can automatically sync this table every 5 minutes to ensure your users get an up-to-date view of their usage. Because Hightouch provides automatic diffing from the previous sync, only changed records will be upserted to your production database, minimizing data volume.
You can create billing-related alerts and notifications for Slack, email, or almost any system using Hightouch. Like all syncs with Hightouch, you can configure your alerts using standard SQL or the Hightouch UI.
Improve customer experiences by helping customers track their spending.
- Customers can set soft limits to receive an email when they have hit their soft cap.
Empower sales by sending Slack messages when accounts hit their caps.
- Increase conversions by setting up alerts to trigger sales or automated marketing outreach before a trial ends.
- Run proactive upsells by giving sales and success teams real-time spend notifications in the systems they already use, such as Slack and Salesforce.
Using Hightouch, SaaS companies can efficiently implement usage-based billing with accurate and auditable usage data synced consistently across tools and platforms.
If you want to implement usage-based pricing with Hightouch today, you can learn more by requesting a demo.