
The following is a guest post from Dio Favatas, Head of Financial Services Adtech & Identity Strategy at Capgemini. Capgemini is an AI-powered global business and technology transformation partner that delivers end-to-end services and solutions across strategy, technology, design, engineering, and business operations.
In part one of this series, we explored why composable CDPs are becoming the preferred architecture for financial institutions: they allow organizations to activate customer data directly from the warehouse without copying sensitive data into third-party systems.
But before a financial institution can personalize experiences, coordinate outreach across lines of business, or measure marketing performance accurately, it first needs a reliable understanding of who the customer actually is across the organization.
That is the role identity resolution plays, and what we’ll explore in this post.
What is identity resolution?
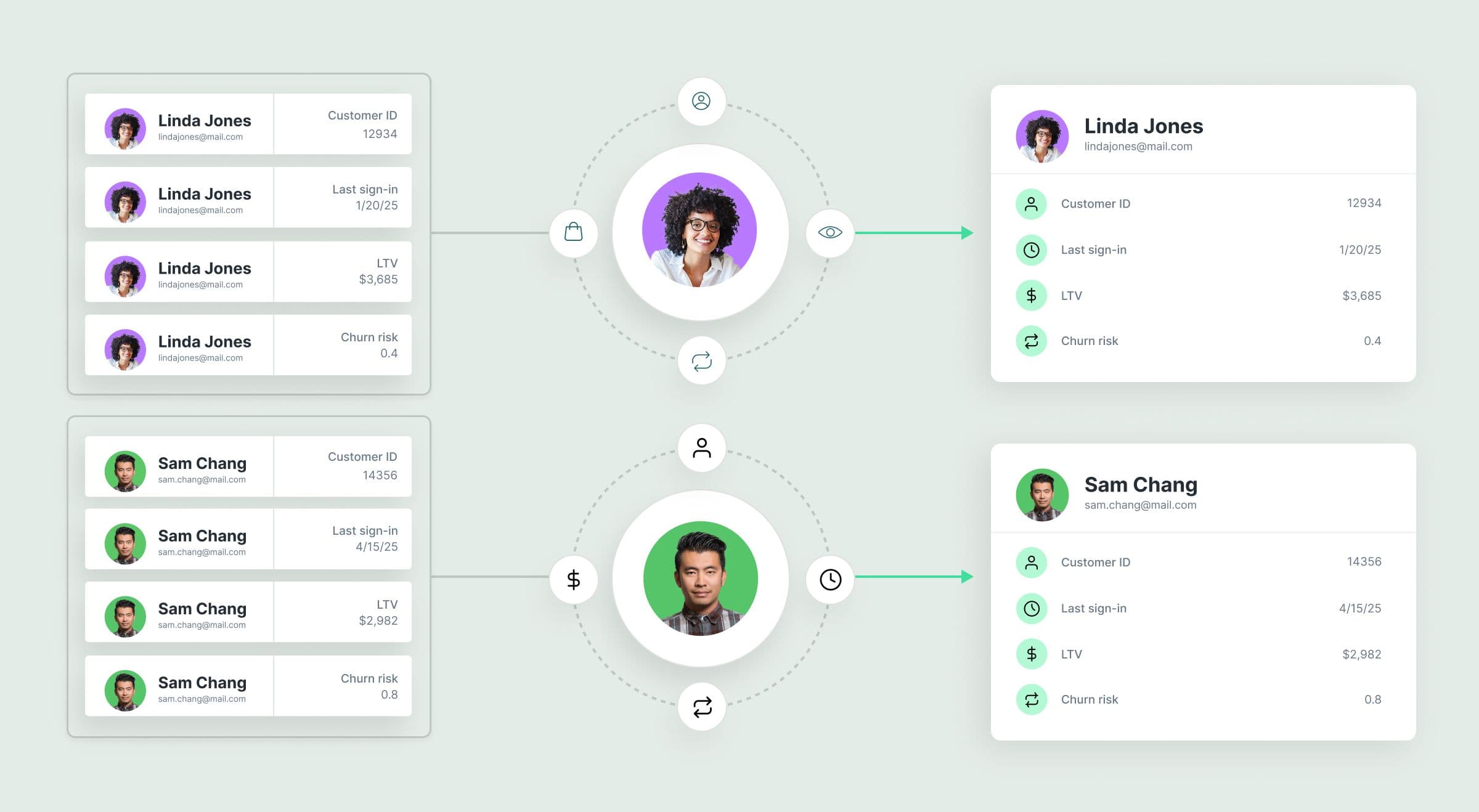
Identity resolution is the process of connecting customer signals across systems, devices, products, and channels into a single, unified customer profile, often referred to as a customer 360. For financial institutions (FIs), that means connecting checking accounts, mortgages, credit cards, and wealth relationships into a coherent customer profile the business can actually operate against.
Without that identity layer, most FIs end up marketing to isolated product holders rather than complete customer relationships. A credit card team may not know a customer also holds a mortgage. Wealth and retail banking teams may coordinate poorly or market independently. And suppression, personalization, and measurement all become fragmented as a result.
Why identity resolution matters more in financial services
Every industry deals with fragmented customer data, but financial institutions face a uniquely complex challenge.
Most banks and financial services organizations operate across multiple products, business lines, and systems that were not originally designed to work together. Customer data is often spread across deposits, lending, wealth management, servicing platforms, mobile apps, call centers, branch systems, and advertising channels.
At the same time, financial institutions also sit on some of the richest customer data in any industry, including transaction behavior, product ownership, household relationships, account hierarchies, credit signals, advisor relationships, and life events.

That data creates enormous opportunities for personalization, measurement, and customer growth, but only if the FI can connect those signals into a usable customer profile.
Why traditional identity resolution creates risk for financial institutions
The conventional approach to identity resolution in marketing involves sending customer data to a third-party graph vendor who matches, deduplicates, and enriches it against their own network of identity signals, then returns a resolved identity spine for targeting and activation.
In most industries, this is a reasonable trade-off. In financial services, the regulatory, compliance, and security environment fundamentally change the calculus, because the intensity of the guardrails that protect customer data inside an FI's walls means that the moment data leaves that environment, a cascade of review processes, legal approvals, and risk assessments begins that can take months to resolve and often ends with the answer being no.
What that means in practice for FI marketing teams is that even when the appetite exists to build sophisticated, identity-driven programs, the organizational friction of clearing the data governance path to do it through a third-party environment creates a ceiling on what is achievable. The more productive question is not how to navigate that friction, but how to architect around it entirely by keeping the identity resolution process inside the institution's own environment from the start.
How composable identity resolution changes the model
Identity resolution with a Composable CDP like Hightouch changes where identity matching happens.
Instead of moving customer data into a separate external platform, identity resolution runs directly within the institution’s own cloud environment and data warehouse, typically inside the institution’s own Virtual Private Cloud (VPC), a private, secured cloud environment controlled by the institution itself.
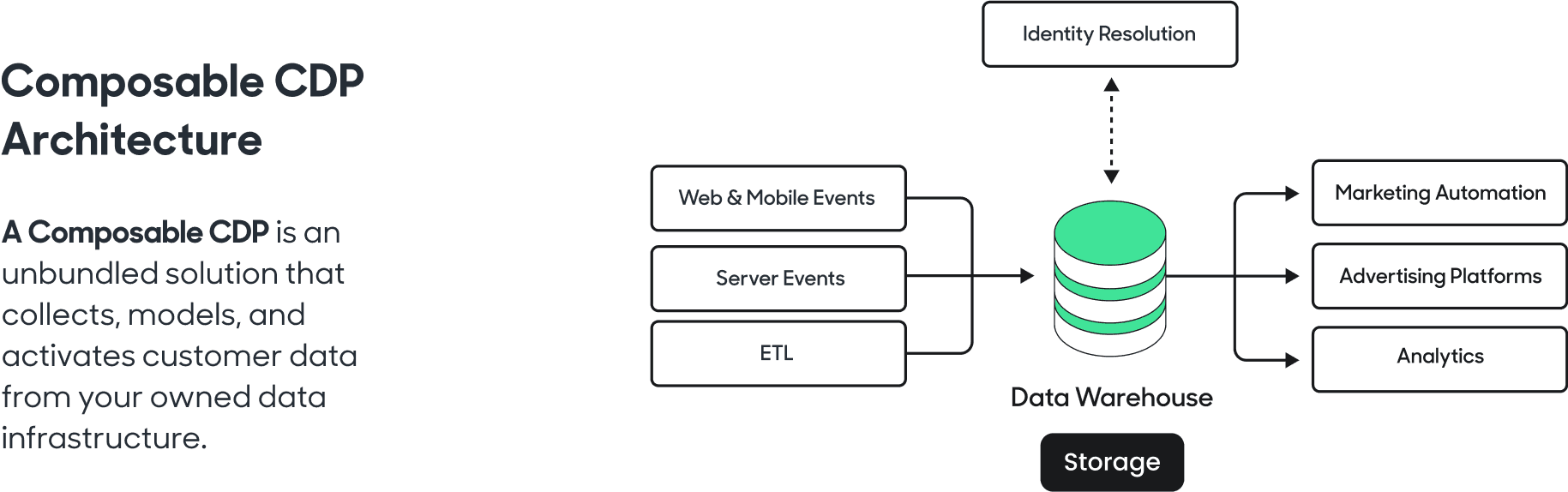
In this model, the matching logic, graph rules, deduplication algorithms, and resolved identity spine all remain within the institution’s existing security perimeter, inheriting its governance controls, certifications, and data residency requirements.
Compliance posture is inherited automatically rather than requiring re-review each time a new data source is introduced. And the institution's own data science team can build, iterate, and improve matching quality using the full depth of signals available in the warehouse, including signals that would never be permissible to share outside the institution's walls.
This architecture also eliminates a dependency that most FI marketing teams do not fully account for until it becomes a problem: when your identity graph lives in a third-party environment, your visibility into how matches are made, what signals are weighted, and whether the resolved identities meet your own compliance standards for permitted data use is inherently limited.
When the graph lives inside your own environment, it is auditable, inspectable, and governed by your own rules rather than a vendor's proprietary methodology.
Real-world identity resolution use cases in financial services
This is the part of the conversation that matters most to a marketing leader: what does a properly constructed, first-party identity graph running natively inside the institution’s own VPC let you do that you cannot do today?
Cross-line-of-business (LOB) profile assembly. Most large financial institutions have mortgage customers they do not know are also credit card customers, wealth clients who have a checking relationship the private bank has never connected to, and small business owners whose business and personal identities have never been linked.
A persistent first-party identity graph makes it possible to see and market to the full customer relationship rather than a single product relationship.
Suppression and governance at the identity layer. When identity resolution runs inside the institution’s own environment, protected-class suppression, consent management, and permitted data use policies can be enforced directly at the identity layer before audiences are activated downstream.
This makes governance native to the identity graph itself rather than bolted on later in the activation process.
Measurement and attribution. Attribution and incrementality measurement in financial services require connecting media exposure to conversion events across channels and over time, which depends on having a stable, persistent identity to anchor those connections.
A resolved first-party identity graph built directly in the warehouse creates a more durable measurement foundation than one dependent on third-party match keys that can be deprecated, restricted, or compromised.
What a composable identity stack looks like in practice
Putting this together, a working architecture for composable identity resolution typically includes:
- Customer data across every line of business flowing into a governed cloud data warehouse
- Identity matching and graph construction running directly inside the institution’s own environment
- Institution-defined matching rules and governance controls
- Self-service audience creation and activation for marketing teams
- Downstream activation into media, CRM, and measurement platforms without duplicating sensitive customer data externally
This is not futuristic architecture. It is what the composable stack makes achievable today, and it is the natural extension of the warehouse-native CDP model described in part one into the identity layer.
What to evaluate when assessing identity resolution solutions
A few things worth verifying as you begin conversations with vendors and internal stakeholders:
True VPC residency. Does the solution actually run within your own cloud environment, or does it require data to be sent to an external environment for processing before being returned? The distinction matters enormously from a compliance standpoint, and the answer is not always as clear as vendor positioning suggests.
Graph rule transparency and auditability. Can your data science and compliance teams inspect, modify, and audit the matching rules that govern how identities are constructed? A graph you cannot audit is a governance liability regardless of where it lives.
Cross-LOB data model support. Can the identity layer ingest and connect non-user entities including account hierarchies, household relationships, business and personal identity linkages, and advisor-client relationships? FI data models are complex, and identity resolution tooling built for simpler data environments will not handle that complexity reliably.
Governance inheritance. Do your existing data access controls, consent records, and permitted data use rules flow through into the identity graph and into downstream audience activation automatically, or does compliance have to be re-enforced manually at every activation step?
Time to production. Can you stand up a production-grade resolved identity graph in weeks rather than quarters, so that marketing programs can begin benefiting from improved identity before the next planning cycle?
Closing thoughts
Financial institutions have spent years building data warehouses that contain some of the richest customer intelligence in any industry, and they have largely been unable to put it to work for marketing because the tools built to activate that intelligence were designed for environments where data portability was an acceptable trade-off. For FIs, it never was.
VPC-resident identity resolution is the architectural move that changes that equation, and the composable stack is what makes it accessible to marketing teams without requiring a multi-year data engineering program to get there.
In the next post, we’ll explore how a Composable CDP unlocks deeper personalization through a more flexible customer data model, making it possible to personalize around products, applications, households, and the full complexity of customer relationships, rather than being constrained to the limited data model of a traditional CDP.

















