To set up identity resolution rules, you must first configure your input models and select the appropriate identifiers.
This page goes through process of creating models, selecting identifiers, and customizing your resolution operations:
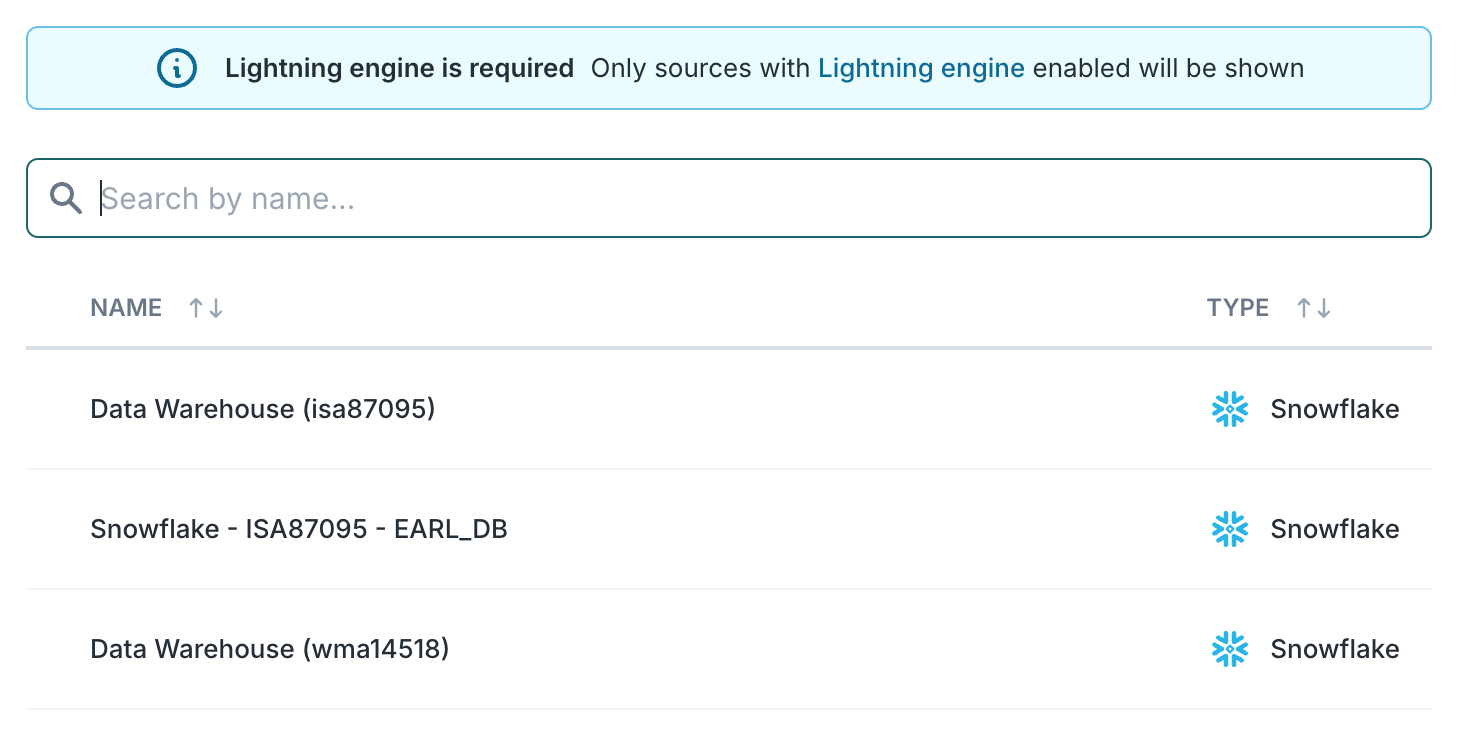
1. Select a source
Pick the data source which contains the data you want to resolve identities across.
Since identity resolution runs on your data warehouse, each identity graph can only be used with a single data source, but you can always create additional identity graphs using other data sources.
Identity resolution only works with sources which have Lightning Engine enabled, since it writes tables back to your warehouse, and only supports Snowflake, Databricks, and BigQuery.
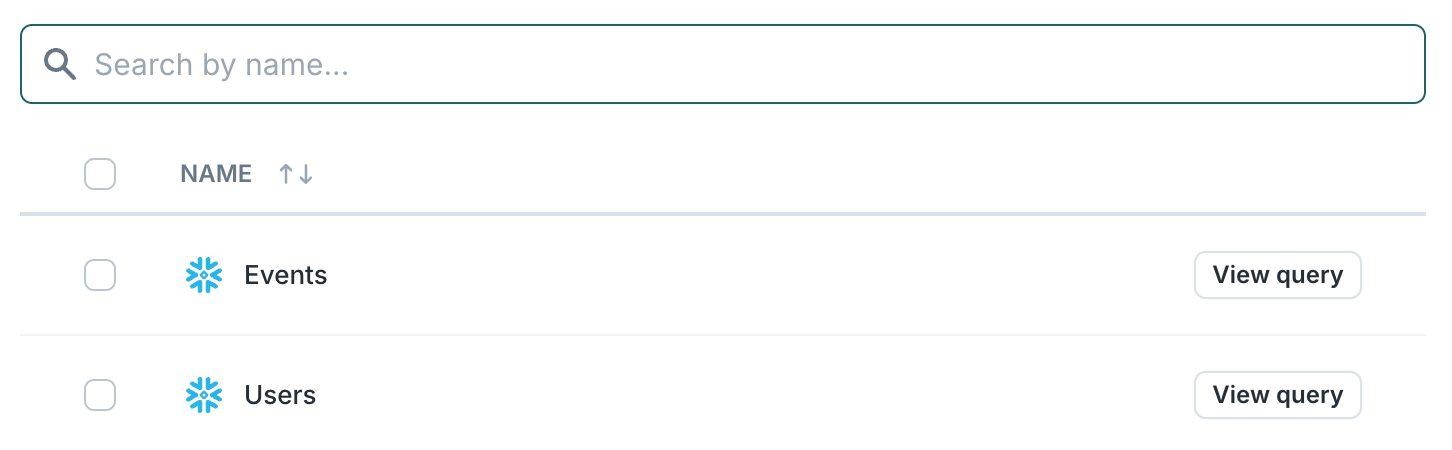
2. Select model(s) to resolve and dedupe across
Identity resolution can take models you've defined under Activation and processes all the rows from the selected models to resolve identities as well as dedupe within and across selected models.
Models must have a timestamp to get processed through IDR. For event models, this should be the timestamp of the event. For non-event models, an updated_at column or a column that represents the latest timestamp a row got updated. If no such timestamp column exists, you can add one using a SQL query to define the model and appending a CURRENT_TIMESTAMP column. Identity resolution uses the timestamp to efficiently processes only net-new or updated rows on incremental IDR runs.
3. Select identifier(s)
After you select your model, you need to configure which identifiers are present on this model. You can choose from Hightouch's default options, or you can create your own by typing anything into the identifier text box.
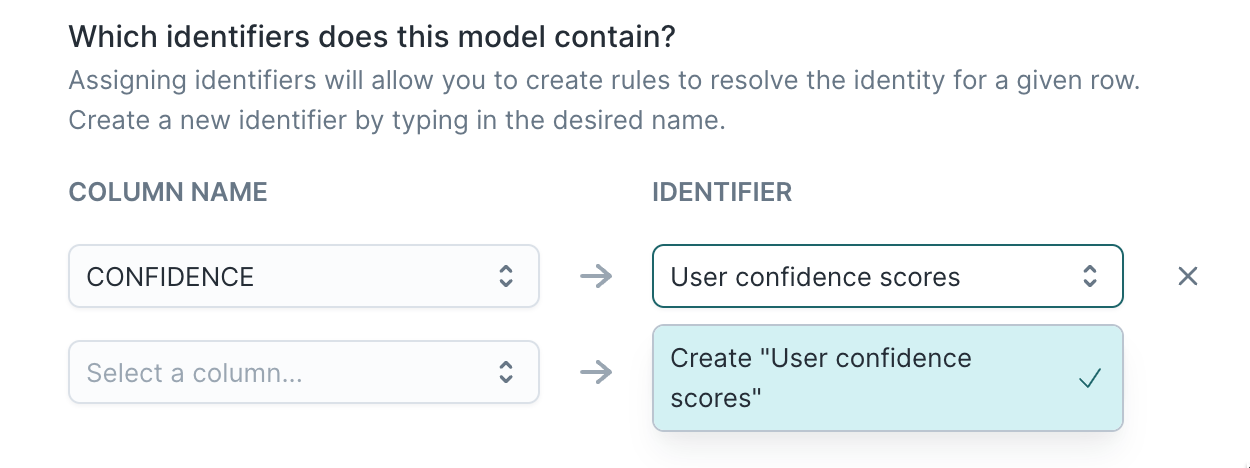
Identifiers are used to match and merge records into a profile.
You must map the identifier to a column in one or more models to use it in a merge or limit rule.